Custom GOAP Implementation: Because why settle for easy when you can have more fun?

Before we begin, let’s set the scene: there’s already a perfectly good (and free!) GOAP (Goal-Oriented Action Planning) implementation available here: https://github.com/crashkonijn/GOAP. But in a glorious fit of curiosity (or was it recklessness?), I decided to build my own system from scratch. Why? To truly grasp how it works, and because I might have downed a bit too much coffee that day.
The result? A system broken down into simple, modular components that are (fingers crossed) easy to debug. Let’s dive into this homemade GOAP approach, tailor-made to blend seamlessly with our Refuge universe.
GOAP: The Theory, Plan Smart, or Crash and Burn
GOAP (Goal-Oriented Action Planning) is a clever method of giving AI some real autonomy without coding a rigid step-by-step sequence. The idea? Let the AI dynamically choose which actions to perform to reach a given objective, based on the current state of the world.
A GOAP system typically stands on four main pillars:
- World state: A set of facts (booleans, values, etc.) describing the environment.
- Goals: Desired final states (e.g., “Have enough water”).
- Actions: Each has prerequisites (what must be true to do it) and effects (what changes in the world as a result).
- The planner: A mastermind that figures out the optimal route (sequence of actions) to achieve a goal.
This model allows for adaptive AI that can react to changes. If a resource disappears or an action fails, the agent can recalculate a new plan, no need to rewrite everything from scratch. Magical? Not exactly. But it sure does feel that way.
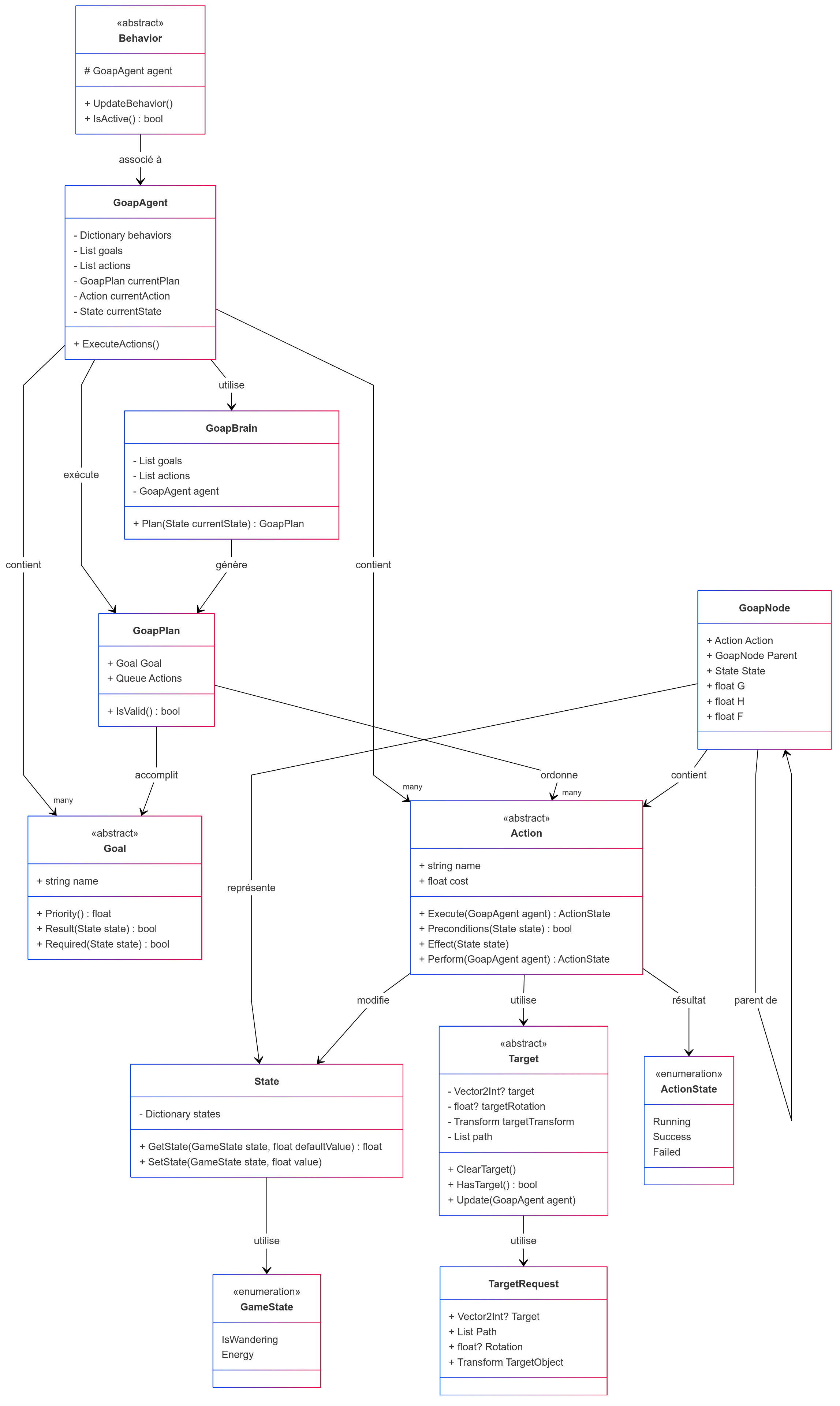
Overview of the GOAP Implementation in Refuge
Our custom GOAP setup in Refuge is arranged in a modular structure with the following components:
- GoapAgent: The agent’s brain, coordinating planning and execution.
- Goal: A clear intention with a priority level.
- Action: An operation the agent can perform. It has preconditions, effects, a duration, and a cost.
- GoapBrain: The planner in charge of figuring out the optimal plan.
- GoapNode: A node in the planning graph.
- GoapPlan: The final plan, expressed as a queue of actions.
- State: A dictionary of key-value pairs describing the world state.
- Target/TargetRequest: Representation of potential action targets.
- Behaviors: Handle the real-world execution of an action (like moving or interacting).
We split decision-making (planning) from actual execution (behaviors), keeping the system neat, flexible, and easier to maintain.
Architecture Diagram
Class-by-Class Breakdown
Goal: The Desire That Drives
A Goal is an objective the agent aims to fulfill. In Refuge, a Goal isn’t just a vague notion like “spread sunshine and rainbows.” No, it’s a very specific world state you want (for instance, “collect food” or “reduce stress levels”).
Each Goal includes:
- A State defining the conditions that mark the goal as achieved.
- A priority level, because even AI can’t do everything at once.
- An
IsRelevantmethod to determine if this goal is worth pursuing given the current world state.
The agent checks these goals at each planning tick. If multiple goals are valid, the system picks the one with the highest priority. Think of it as the moral compass of the agent, but in C#.
(Note: In Refuge, goals are designed to be easily extended. You want a goal called “score epic loot”? Just code a new class and define the target state. Simple as that.)
Action: The Go-Getters
If Goal is the “what,” an Action is the “how.” An action is a task the agent can execute to alter the world and inch closer to its objective. But it’s not a free-for-all. Every Action is tidy, with rules and constraints.
An Action contains:
- Preconditions: What needs to be true for it to be performable (e.g., a target must be available, the agent must be close enough, or not exhausted).
- Effects: How this action changes the world state (e.g., after “Drink,” the agent is no longer thirsty).
- A cost: Used in planning to favor more efficient paths.
- An execution time (if it’s not instantaneous).
- A TargetRequest: The kind of target this action needs (if any).
Each action also has callbacks (OnEnter, OnExit, Tick) to handle ongoing behavior. That’s where the magic happens: while running, an action can call a corresponding Behavior to move around, interact with objects, etc.
Everything is data-driven, so you can add new actions without rewriting the planner. Just define your conditions and effects, and the planner happily picks it up.
In short, an Action is the Swiss Army knife of the system. And like any good tool, it’s all about how you use it.
State: The World’s Journal
State is basically the world’s diary, or a big bucket of facts. It stores the current (or desired) state of the world using key-value pairs. In Refuge, we opted for a Dictionary<string, object> to stay flexible.
A State can hold anything: a boolean for “Has water,” an integer for resource counts, or a reference to some target. As long as it’s serializable, it’s fair game.
Key methods include:
- Contains: Checks if one
Statemeets the conditions of another. - Apply: Merges another
Statein, updating values. - Clone: Because we want to test hypothetical changes without messing up the real world.
State appears everywhere:
- As the initial world conditions
- In action effects
- In goal conditions
- In the plan-building nodes
So if Action is the muscle, and Goal the motivation, then State is the logical brain guiding the process. It’s quiet but absolutely essential.
Target / TargetRequest: The Action’s Focus
Rarely does an action happen in a cosmic vacuum. Usually, it needs a target, some resource, an object, or a location. Enter Target and TargetRequest:
Targetwraps a position, an entity, or any point of interest the action should aim for, providing a unified interface.TargetRequestexpresses a need, like “I need a place to sleep” or “I’m looking for a crate of supplies.” It defines the type of target we’re seeking, any additional filters, and how we assign the resulting target.
Workflow:
- The action presents a
TargetRequest. - The system attempts to fulfill this request by handing over a
Target. - The action executes using that specific target.
This is a flexible, generic approach ideal for a dynamic game like Refuge, where actions might aim at all kinds of shifting objects.
In a nutshell, if State describes the world, TargetRequest asks, “So, what am I actually interacting with?”
Behaviors: Making It Happen
Behaviors are the worker bees of GOAP. Once an action is planned and approved, it needs someone to handle it, and that’s the job of Behavior.
Each action can be linked to a specific Behavior, which does the nitty-gritty:
- Move to a location (
MoveBehavior) - Play an animation
- Wait some duration
- Trigger an interaction with an object
A Behavior is all about bringing the action to life. It works hand in hand with the action, calling the right methods in Tick(), handling transitions (EnterState, ExitState), and telling the agent when it’s done.
Behaviors can also have sub-states (like MoveState) to structure their internal processes.
They’re designed to be reusable across different actions, giving you a broad, flexible toolkit without duplicating code. Basically, they’re like Unity scripts... that actually do something useful.
In short, without Behavior, your AI would stand around philosophizing. With Behavior, it’s an adventurer ready to loot, eat, run... and maybe die a heroic death.
GoapBrain: The Subtle Mastermind
GoapBrain is the actual strategy engine. Its job? Find the best route to achieve whichever Goals are in play, using the available Actions.
How does it work?
- It takes the world’s current
State. - It checks the selected
Goal. - It builds a graph of
GoapNodes, each node reflecting a possible world state after performing a certain action. - It then uses A* search to locate the shortest (or cheapest) path to the goal.
All the real planning logic lives in GoapBrain. It tests out actions, sees what’s possible, tallies costs, and eventually spits out a GoapPlan for the agent to execute.
So GoapBrain is basically the puppet master: you can’t see or hear it, but without it, your AI would wander aimlessly.
GoapNode: Stepping Stones to Success
GoapNode represents an intermediate state in the plan. Think of it as a snapshot of the world after running one or more actions.
Each GoapNode holds:
- A
Statedescribing the world at this step. - A reference to the action that led here.
- A running cost accumulated so far.
- A pointer to the previous node for reconstructing the path later.
In practice, GoapBrain creates and evaluates these nodes as it does its A* search, exploring possibilities and tallying up costs until it finds the best plan. They’re like squares on a chessboard: you look at several, but only the best path wins.
Without them, we couldn’t track our decisions, and we’d have no plan. They’re crucial for structuring the AI’s progress toward success.
GoapPlan: The (Almost) Perfect Plan
GoapPlan is simply the final representation of the route computed by GoapBrain. Once the planner is done, it compiles a GoapPlan consisting of a sequence (or queue) of actions to be performed in order.
It includes:
- An ordered list of
Actionobjects the agent should execute. - The total cost of carrying out that plan.
Once complete, the plan is handed off to the GoapAgent, which proceeds to run each action in turn. It’s like a recipe, follow each step carefully and you’ll (probably) end up with success (though in Refuge, success usually means survival rather than a delicious cake).
The strength of GOAP is this straightforward approach: if something fails, or the world changes, you can quickly compute a new plan. So it’s pretty much the perfect plan... right up until it isn’t.
GoapAgent: The Ultimate Executor
Finally, GoapAgent is the main character in this story. It perceives the world, sets its goals, calculates a plan, and most importantly, carries it out.
Its main jobs are:
- Perception: Obtain and keep track of the current
Stateof the world. - Goal Selection: Decide which
Goalis relevant given the situation. - Planning: Ask
GoapBrainfor a freshGoapPlanwhenever there’s no valid plan. - Execution: Perform each action in the plan, invoking the necessary
Behaviorsand checking results. - Handling Surprises: Recalculate a plan if an action fails or the world changes drastically.
GoapAgent orchestrates the entire GOAP process, acting as the conductor of all the system’s components. Without it, goals would just be wishes, plans would remain theories, and actions would never get off the ground.
In short, GoapAgent is the lifeblood of the system, breathing life into all that GOAP theory in Refuge.
Conclusion
This homemade GOAP setup in Refuge has been a delightful (and caffeinated) adventure, digging into how goal-driven AI really works. Sure, there are tried-and-true solutions out there, but sometimes you just need to roll up your sleeves and get your hands dirty.
The upshot? A modular, adaptable, and flexible system, well-suited for Refuge’s unpredictable environment. And honestly, what’s more satisfying than watching your virtual agents handle problems (mostly) on their own, thanks to a well-thought-out plan?
Ultimately, this whole experience taught me one big lesson: whether it’s in code or in a zombie-ridden wasteland, having a solid plan, and plenty of coffee, makes all the difference.
Avant de commencer, remettons les choses dans leur contexte : il existe déjà une implémentation de GOAP (Goal-Oriented Action Planning) qui fonctionne très bien et qui est même gratuite. Elle est disponible ici : https://github.com/crashkonijn/GOAP. Mais bon... dans un élan de curiosité (ou de masochisme ?), j'ai décidé de réimplémenter mon propre système. Pourquoi ? Pour comprendre comment ça marche. Et aussi parce que j'avais un peu trop de café ce jour-là.
Le résultat ? Un système décomposé en composants simples, modulaires et faciles à débugguer (si si, promis). Voici un tour d'horizon de mon GOAP maison, pensé pour s'intégrer parfaitement à l'univers de Refuge.
GOAP, côté théorie : planifier intelligemment, ou l'art de ne pas foncer dans le mur
GOAP (Goal-Oriented Action Planning), c'est une manière de faire réfléchir nos IA sans leur programmer à l'avance une suite d'actions rigide. L'idée ? Laisser l'IA choisir dynamiquement les actions à effectuer pour atteindre un objectif donné, en fonction de l'état actuel du monde.
Un système GOAP repose sur quatre grands piliers :
- L'état du monde : une collection de faits (booléens, valeurs, etc.) qui décrivent l'environnement actuel.
- Les objectifs (Goals) : des états finaux désirés (ex : « avoir de l'eau »).
- Les actions : chacune a des préconditions (ce qu'il faut pour qu'elle soit faisable) et des effets (ce qu'elle change dans le monde).
- Le planificateur : un petit malin qui réfléchit au chemin optimal (séquence d'actions) pour atteindre un objectif.
Ce modèle permet une IA adaptative, capable de s'ajuster à l'évolution du monde. Si une ressource devient indisponible ou si une action échoue, l'agent peut recalculer un nouveau plan, sans avoir besoin de tout recoder à la main. Magique ? Non. Mais diablement efficace.
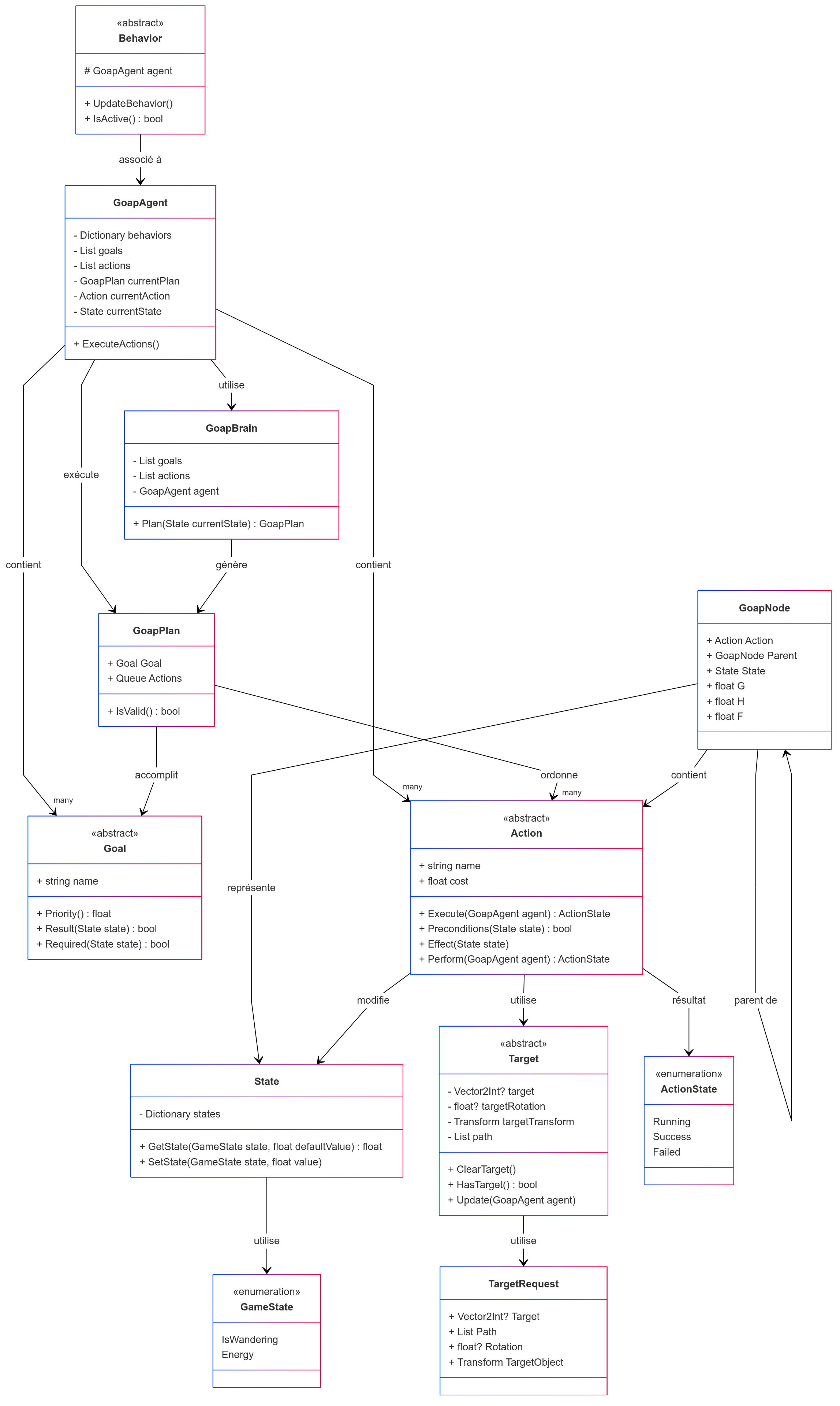
Vue d'ensemble de l'implémentation GOAP dans Refuge
L'implémentation custom de GOAP dans Refuge suit une architecture modulaire composée des éléments suivants :
- GoapAgent : le cerveau de l'agent, qui coordonne la planification et l'exécution.
- Goal : définit une intention claire à atteindre, avec une priorité.
- Action : une opération que l'agent peut effectuer. Elle a des préconditions, des effets, une durée et un coût.
- GoapBrain : le planificateur, responsable de la recherche d'un plan optimal.
- GoapNode : un nœud dans le graphe de planification.
- GoapPlan : le plan final sous forme de file d'actions.
- State : un dictionnaire d'état du monde sous forme de clé-valeur.
- Target/TargetRequest : représentation de cibles d'action potentielles.
- Behaviors : permettent l'exécution concrète d'une action (par exemple : se déplacer, interagir).
Cette architecture s'appuie sur une séparation claire entre la décision (planification) et l'exécution (behaviors), facilitant la maintenance et l'évolution du système.
Schéma d'architecture
Détail classe par classe
Goal : l’intention avant l’action
La classe Goal représente un objectif que l’agent souhaite atteindre. Dans Refuge, un Goal n’est pas une simple idée vague du style « faire le bien autour de soi », non non. C’est un état clairement défini du monde que l’on veut réaliser (par exemple : « avoir de la nourriture », ou « réduire le niveau de stress »).
Chaque Goal est composé de :
- Un State qui définit les conditions à atteindre pour que le goal soit considéré comme accompli.
- Une priorité, parce qu’on ne peut pas tout faire en même temps (même les IA doivent prioriser !).
- Une méthode
IsRelevantqui permet à l’agent de savoir si ce goal mérite d’être poursuivi dans l’état actuel du monde.
Côté architecture, le Goal est consulté par l’agent à chaque tick de planification. Si plusieurs goals sont valides, le système choisit celui avec la plus haute priorité. Bref, c’est un peu la boussole morale de l’agent, mais en version C#.
(À noter : dans Refuge, les goals sont conçus pour être facilement extensibles. Tu veux un goal « collecter du loot épique » ? T’as juste à coder une nouvelle classe et définir l’état cible. Facile comme bonjour.)
Action : les petits soldats du plan
Si Goal est le « quoi », alors Action est le « comment ». Une Action, c’est une tâche que l’agent peut exécuter pour transformer le monde et s’approcher de son objectif. Mais attention : ici, on ne parle pas d’actions en mode YOLO. Non, chaque Action est une entité bien rangée, encadrée, avec règles et conditions.
Une Action contient :
- Des préconditions : ce qui doit être vrai pour qu’on puisse l’effectuer (ex : avoir une cible, être proche de quelque chose, ne pas être fatigué).
- Des effets : ce que l’action modifie dans l’état du monde (ex : après « Boire », l’agent n’a plus soif).
- Un coût : utilisé pendant la planification pour privilégier les plans plus efficaces.
- Un temps d’exécution (si l’action n’est pas instantanée).
- Un TargetRequest : la cible que cette action nécessite pour s’exécuter correctement (optionnelle).
Chaque action dispose aussi de callbacks (OnEnter, OnExit, Tick) pour gérer l’exécution dans le temps. C’est là que la magie opère : pendant l’exécution, l’action peut faire appel à un Behavior pour animer un déplacement, interagir avec un objet, etc.
Le tout est encapsulé de manière à ce que les actions soient data-driven : on peut en ajouter de nouvelles sans toucher au planificateur. Ajoute une classe, définis les préconditions et effets, et voilà ! Le planificateur saura s’en servir.
Bref, Action, c’est le couteau suisse du système. Et comme tout bon outil, il faut juste bien savoir s’en servir.
State : la mémoire du monde
La classe State, c’est un peu le journal intime du monde — ou plutôt une grosse table de vérité. Elle stocke l’état actuel du monde (ou l’état désiré pour un objectif) sous forme de paires clé/valeur. Dans Refuge, on a choisi de représenter cela avec un Dictionary<string, object>, histoire de rester souple.
Un State peut contenir n’importe quoi : un booléen qui dit si on a de l’eau, un entier qui indique le nombre de ressources, ou une référence vers une cible. Tant que c’est sérialisable, c’est stockable.
Les fonctions clés de cette classe :
- Contains : pour vérifier si un sous-ensemble d’un autre
Stateest satisfait. - Apply : pour fusionner un autre
Stateet mettre à jour les valeurs. - Clone : parce qu’on veut pouvoir tester des hypothèses sans casser le vrai monde.
State est utilisé partout :
- Dans les conditions initiales du monde
- Dans les effets d’action
- Dans les conditions de goal
- Dans la construction des noeuds du planificateur
En résumé, si Action est le muscle et Goal la motivation, alors State est le cerveau rationnel qui suit la logique. Il ne fait pas de bruit, mais sans lui, rien ne fonctionne.
Target / TargetRequest : les yeux de l’action
Une Action ne se fait pas toujours dans le vide intersidéral. Souvent, elle nécessite une cible : une ressource, un objet, un endroit... Bref, quelque chose à viser. C’est là qu’interviennent Target et TargetRequest.
- La classe
Targetencapsule une position, une entité, ou n’importe quel point d’intérêt qu’une action pourrait viser. C’est une sorte de wrapper générique qui permet de manipuler des cibles de manière uniforme. TargetRequest, lui, représente un besoin : « j’ai besoin d’un endroit où dormir », ou « je cherche une caisse de vivres ». Il définit le type de cible recherchée, les filtres éventuels, et l’assignation de la cible si une correspondance est trouvée.
Le workflow est le suivant :
- L’action exprime un
TargetRequest. - Le système essaie de satisfaire cette demande en lui fournissant un
Target. - L’action peut alors s’exécuter avec cette cible concrète.
C’est un système souple et générique, parfait pour un jeu comme Refuge où les actions peuvent viser toutes sortes d’éléments dynamiques.
En somme, si State décrit le monde, TargetRequest pose la question : « Et moi, je tape sur quoi ? »
Behaviors : faire, bouger, vivre
Les Behaviors, ce sont les petites mains du système GOAP. Une fois qu’une action est planifiée et validée, il faut bien quelqu’un pour l’exécuter — et ce quelqu’un, c’est le Behavior.
Chaque action peut être associée à un Behavior spécifique, qui se charge de l’exécution concrète :
- Se déplacer vers une cible (
MoveBehavior) - Jouer une animation
- Attendre un certain temps
- Déclencher une interaction avec un objet
Le rôle du Behavior, c’est donc d’apporter l’aspect « moteur » du système. Il travaille main dans la main avec l’action, en appelant les bonnes méthodes dans Tick(), en gérant les transitions (EnterState, ExitState), et en notifiant l’agent lorsque c’est terminé.
Les Behaviors peuvent également posséder leurs propres sous-états (MoveState, par exemple), afin de mieux structurer l’enchaînement d’étapes internes.
Ils sont conçus pour être réutilisables entre différentes actions, permettant une grande souplesse sans dupliquer le code. En bref, c’est un peu comme des scripts Unity... mais qui font des trucs utiles.
Conclusion : sans Behavior, ton IA est un philosophe immobile. Avec Behavior, elle devient un aventurier prêt à looter, manger, courir... et mourir de manière glorieuse.
GoapBrain : le stratège silencieux
Le GoapBrain, c’est le véritable planificateur stratégique du système. Sa mission ? Trouver le meilleur chemin pour atteindre les objectifs définis par les Goals en utilisant les Actions disponibles.
Comment ça marche en pratique ?
- Le cerveau récupère l’état actuel du monde (
Stateinitial). - Il prend le
Goalsélectionné par l’agent. - Il construit progressivement un graphe composé de
GoapNodes, chaque nœud représentant un état intermédiaire après une action spécifique. - Il utilise une recherche A* pour trouver le chemin le plus court (ou le moins coûteux) vers l'objectif.
C’est dans le GoapBrain que réside la logique pure de planification. Il teste les différentes actions disponibles, explore les possibilités, évalue les coûts, et finit par proposer un GoapPlan qui sera exécuté par l’agent.
Bref, le GoapBrain, c’est l’éminence grise : tu ne le vois pas, tu ne l’entends pas, mais sans lui, ton IA tournerait en rond sans fin.
GoapNode : les étapes vers la victoire
Le GoapNode représente un état intermédiaire dans la planification. Chaque nœud est une « photographie » du monde à un instant précis après l’exécution d’une ou plusieurs actions.
Chaque GoapNode contient :
- Un
State(l'état du monde à ce stade). - Une référence vers l’action qui a permis d’atteindre ce node.
- Un coût cumulé depuis le début du plan.
- Un lien vers le nœud précédent pour reconstruire le chemin complet à la fin.
En pratique, le GoapBrain crée et évalue ces nœuds pendant la recherche A*, explorant les chemins possibles et calculant les coûts jusqu’à trouver le plan optimal. En gros, les GoapNodes, c’est comme les cases sur un échiquier : on en explore plusieurs, mais seul le meilleur chemin est retenu.
Sans eux, pas de mémoire des choix faits, et donc pas de plan. Ils sont essentiels pour structurer la réflexion de l’IA vers la victoire.
GoapPlan : le plan parfait (ou presque)
Le GoapPlan est simplement la représentation finale du chemin calculé par le GoapBrain. Une fois que le planificateur a terminé ses calculs, il construit un GoapPlan composé d'une file d’actions à exécuter dans l’ordre.
Ce plan contient :
- Une liste ordonnée d’actions (
Action) à réaliser par l’agent. - Le coût total accumulé pour réaliser le plan.
Une fois établi, le plan est remis à l’agent (GoapAgent) qui se charge de son exécution, action par action. C’est un peu comme une recette de cuisine : chaque étape doit être suivie scrupuleusement pour obtenir le résultat voulu (sauf que là, au lieu d'un gâteau, on obtient généralement de la survie ou des ressources).
La robustesse de GOAP réside dans cette simplicité apparente : si quelque chose échoue ou si le monde change, le plan peut être facilement recalculé. C’est donc un plan parfait... du moins jusqu’à ce que quelque chose se mette à mal tourner.
GoapAgent : l'exécutant ultime
Enfin, le GoapAgent est l’acteur principal sur la scène. Il représente l’entité capable de percevoir le monde, définir ses objectifs, calculer un plan, et surtout, exécuter ce plan.
Voici ses principales responsabilités :
- Perception : Obtenir et maintenir à jour l’état actuel du monde (
State). - Sélection d'objectif : Déterminer quel
Goalest pertinent en fonction de l’état actuel. - Planification : Demander au
GoapBrainun nouveauGoapPlanlorsqu’il n’a plus de plan valide. - Exécution : Exécuter les actions du plan une par une, en invoquant les
Behaviorsassociés et en surveillant les résultats. - Gestion des imprévus : Réagir et recalculer un plan si une action échoue ou si le monde change significativement.
Le GoapAgent orchestre ainsi tout le processus GOAP, servant de chef d’orchestre aux différentes composantes du système. Sans lui, les objectifs ne seraient que des souhaits, les plans resteraient des hypothèses, et les actions ne seraient jamais plus que des intentions.
En bref, GoapAgent est le cœur vivant du système, donnant vie à toute la mécanique théorique de GOAP dans Refuge.
Conclusion
Cette implémentation maison de GOAP dans Refuge a été une aventure passionnante qui a permis d'approfondir la compréhension des mécanismes de l'intelligence artificielle orientée objectifs. Bien sûr, il existe des solutions déjà éprouvées et fonctionnelles, mais parfois, il faut mettre les mains dans le cambouis pour vraiment saisir les subtilités d'un concept.
Le résultat ? Un système modulaire, évolutif et flexible, parfaitement adapté au contexte dynamique et imprévisible de Refuge. Et puis, honnêtement, quoi de plus satisfaisant que de voir ses agents virtuels se débrouiller tout seuls (enfin presque) grâce à un plan bien pensé ?
Finalement, cette expérience a démontré une chose essentielle : en programmation comme en survie post-apocalyptique, l'important, c'est d'avoir un bon plan... et du café.